01Basics
01Basics
完整代码实现见 Dawnfz-Lenfeng/cs336-basic。
1. BPE Tokenization
1.1 BPE Tokenizer Training
BPE 训练部分主要包括训练流程如下:
- Vocabulary initialzation:用
bytes初始化vocab - Pre-tokenization:对文本分词成
pretoken,计数pretoken以计数token - Pop most frequent pair:pop 出最频繁的
token_pair作为new_token - Merge:把
token中的token_pair合并为new_token,进入循环
完整实现如下:
def train_bpe(
input_path: str | os.PathLike,
vocab_size: int,
special_tokens: list[str],
) -> tuple[dict[int, bytes], list[tuple[bytes, bytes]]]:
vocab = [bytes([i]) for i in range(256)]
merges = []
pretoken_counts = pretokenize(input_path, special_tokens)
pair_counts, pair2pretoken = pretoken2pair(pretoken_counts)
pair_heap = LazyHeap(dict(pair_counts))
num_merges = vocab_size - len(vocab) - len(special_tokens)
for _ in range(num_merges):
pair = pop_most_frequent_pair(pair_heap, vocab)
byte1, byte2 = map(lambda x: vocab[x], pair)
merges.append((byte1, byte2))
vocab.append(byte1 + byte2)
merge_pair(pretoken_counts, pair_heap, pair2pretoken, pair, len(vocab) - 1)
vocab.extend(token.encode("utf-8") for token in special_tokens)
return {i: token for i, token in enumerate(vocab)}, merges
优化思路
Pre-tokenization:主要针对大文件优化,大文件 pretokenize 是瓶颈。在 tinystories 数据集上 load memory 会比较有压力,因此把文件切分成 chunk 多进程 pretokenize。
def find_chunk_bounds(
file: BinaryIO,
split_special_token: bytes,
chunk_size: int = 5 * 1024 * 1024,
) -> list[int]:
"""Chunk the file into parts that can be counted independently"""
file.seek(0, os.SEEK_END)
file_size = file.tell()
file.seek(0)
bounds = [0]
for pos in range(0, file_size, chunk_size):
chunk = file.read(chunk_size)
if (found_at := chunk.rfind(split_special_token)) != -1:
bounds.append(pos + found_at + len(split_special_token))
bounds.append(file_size)
return bounds
Pop most frequent pair:考虑用 LazyHeap 优化 find_max 操作,需要 dict + heap 以实现 O(1) 的查找、更改、删除、max 操作。由于 count 相同时需要比较最大字典序,而 Python 仅支持最小堆,如果仅通过堆操作则需要构造 ReversedPair 对象。
class ReversedPair:
vocab: list[bytes]
def __init__(self, pair: tuple[int, int]):
self.pair = pair
def __lt__(self, other: "ReversedPair") -> bool:
self_pair = (self.vocab[self.pair[0]], self.vocab[self.pair[1]])
other_pair = (self.vocab[other.pair[0]], self.vocab[other.pair[1]])
return self_pair > other_pair
def __eq__(self, other: "ReversedPair") -> bool:
return self.pair == other.pair
def __hash__(self) -> int:
return hash(self.pair)
@classmethod
def set_vocab(cls, vocab: list[bytes]):
cls.vocab = vocab
但实际上创建对象开销会比较高,在频繁的 Pop 中真正需要字典序排序的场景并不多,因此不如 Pop 出所有频率相同的 pair,手动比较字典序性能更好。
def pop_most_frequent_pair(
pair_heap: LazyHeap,
vocab: list[bytes],
) -> tuple[int, int]:
"""Pop the most frequent pair in the vocabulary"""
max_pair, max_count = pair_heap.pop()
vocab_order = (vocab[max_pair[0]], vocab[max_pair[1]])
pairs_to_restore: list[tuple[int, int]] = []
while pair_heap:
top, top_count = pair_heap.top()
if top_count < max_count:
break
# if count is the same, compare their lex order
if (new_order := (vocab[top[0]], vocab[top[1]])) > vocab_order:
pairs_to_restore.append(max_pair)
max_pair, vocab_order = top, new_order
else:
pairs_to_restore.append(top)
pair_heap.pop()
for pair in pairs_to_restore:
pair_heap[pair] = max_count
return max_pair
Merge:得到 new_token 后,需要找到对应的 pretoken 从而更新 pair_count。一方面可以缓存 pair2pretoken ,O(1) 进行查找;另一方面只记录需要更新的 pretoken,增量更新 pair_count。
def merge_pair(
pretoken_counts: Counter[tuple[int, ...]],
pair_heap: LazyHeap,
pair2pretoken: dict[tuple[int, int], set[tuple[int, ...]]],
pair_to_merge: tuple[int, int],
new_token: int,
):
"""Merge a pair of tokens in the pretoken counts, updating the counts of the new and adjacent pairs"""
items_to_merge = [
(pretoken, pretoken_counts[pretoken])
for pretoken in pair2pretoken[pair_to_merge]
]
for pretoken, count in items_to_merge:
new_pretoken, pair_delta = _merge_pretoken(
pretoken, count, pair_to_merge, new_token
)
del pretoken_counts[pretoken]
_remove_pretoken_from_pairs(pretoken, pair2pretoken)
# filter len(pretoken) < 2
if len(new_pretoken) >= 2:
pretoken_counts[new_pretoken] += count
_add_pretoken_to_pairs(new_pretoken, pair2pretoken)
for pair, delta_count in pair_delta:
pair_heap[pair] += delta_count
其中 _merge_pretoken 需要处理比较复杂的边界情况:
def _merge_pretoken(
pretoken: tuple[int, ...],
count: int,
pair_to_merge: tuple[int, int],
new_token: int,
) -> tuple[tuple[int, ...], list[tuple[tuple[int, int], int]]]:
new_pretoken = []
pair_delta = []
i = 0
while i < len(pretoken):
if i + 1 == len(pretoken) or (pretoken[i], pretoken[i + 1]) != pair_to_merge:
new_pretoken.append(pretoken[i])
i += 1
continue
# left adjacent pair
if i > 0:
if new_pretoken[-1] == new_token:
pair_delta.append(((new_token, new_token), count))
# if adjacent pairs have been merged,
# left's (new_token, pretoken[i + 2]) pair has been +count wrongly
pair_delta.remove(((new_token, pretoken[i]), count))
else:
pair_delta.append(((pretoken[i - 1], pretoken[i]), -count))
pair_delta.append(((pretoken[i - 1], new_token), count))
# right adjacent pair
if i + 2 < len(pretoken):
pair_delta.append(((pretoken[i + 1], pretoken[i + 2]), -count))
pair_delta.append(((new_token, pretoken[i + 2]), count))
new_pretoken.append(new_token)
i += 2
return tuple(new_pretoken), pair_delta
1.2 BPE Tokenizer
Tokenizer 实现相对 train_bpe 简单不少,主要接口为 encode: str -> list[int] 和 decode: list[int] -> str。
Encode:encode 过程与 merge 类似,先把文本拆分成 pretoken,按照 merges 列表中的合并顺序迭代合并,最终通过 vocab 转换为 token_ids。
def encode(self, text: str) -> list[int]:
if not text:
return []
if self.special_pattern:
parts = self.special_pattern.split(text)
else:
parts = [text]
ids = []
for part in parts:
if not part:
continue
if part in self.special_tokens:
ids.append(self.encoder[part.encode('utf-8')])
continue
pretokens = [
[self.encoder[b] for b in match.group().encode('utf-8')]
for match in PAT.finditer(part) # pretokenize
]
ids.extend(
self.encoder[token]
for pretoken in pretokens
for token in self._merge_pretoken(pretoken)
)
_merge_pretoken 需要找到合并顺序,因此需要在初始化时额外构造 self.ranks = {pair: i for i, pair in enumarate(merges)}。
def _merge_pretoken(self, pretoken: list[bytes]) -> list[bytes]:
if len(pretoken) < 2:
return pretoken
while len(pretoken) >= 2:
pair_to_merge = min(
zip(pretoken[:-1], pretoken[1:]),
key=lambda pair: self.ranks.get(pair, float("inf")),
)
if pair_to_merge not in self.ranks:
break
new_pretoken = []
i = 0
while i < len(pretoken):
if (
i + 1 < len(pretoken)
and (pretoken[i], pretoken[i + 1]) == pair_to_merge
):
new_pretoken.append(pretoken[i] + pretoken[i + 1])
i += 2
else:
new_pretoken.append(pretoken[i])
i += 1
pretoken = new_pretoken
return pretoken
Decode:decode 非常简单,使用 vocab 查询即可:
def decode(self, ids: list[int]) -> str:
if not ids:
return ""
return b"".join(self.vocab[id] for id in ids).decode("utf-8", errors="replace")
2. Transformer Language Model Architecture
原文档采用自下而上的方式,这里我们采用自上而下的方式。总架构图如下所示:
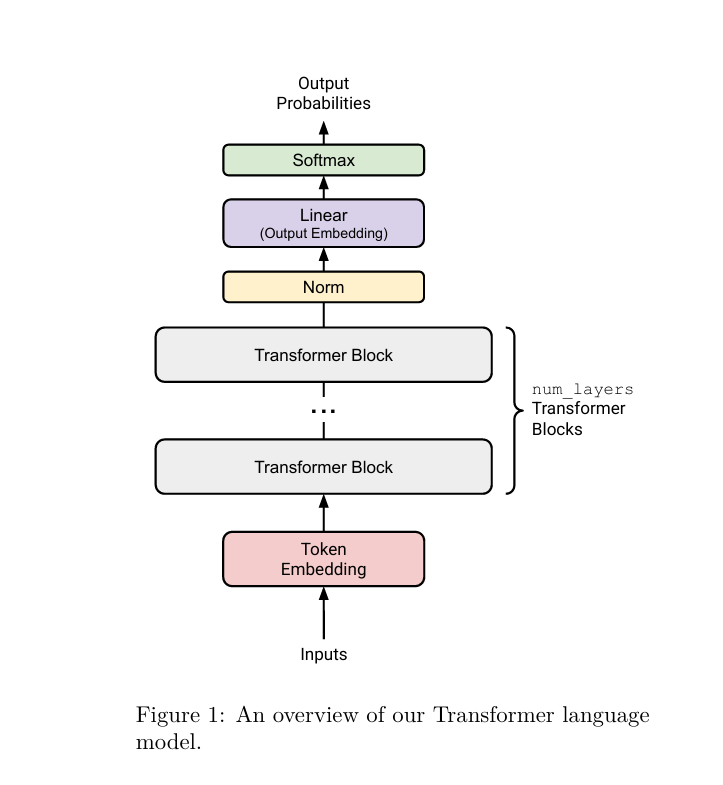
实际只会输出 logits,即到 Linear 层,代码架构如下:
class TransformerLM(nn.Module):
def __init__(
self,
vocab_size: int,
context_length: int,
d_model: int,
num_layers: int,
num_heads: int,
d_ff: int,
rope_theta: float,
):
super().__init__()
self.token_embeddings = Embedding(vocab_size, d_model)
self.layers = nn.ModuleList(
TransformerBlock(d_model, num_heads, d_ff, context_length, rope_theta)
for _ in range(num_layers)
)
self.ln_final = RMSNorm(d_model)
self.lm_head = Linear(d_model, vocab_size)
def forward(
self,
x: Int[Tensor, " ... seq_len"],
) -> Float[Tensor, " ... seq_len vocab"]:
x = self.token_embeddings(x)
for block in self.layers:
x = block(x)
x = self.ln_final(x)
logits = self.lm_head(x)
return logits
2.1 Linear Module
Linear 是最基础的模块,功能为对空间维度进行变换 (..., in_features) -> (..., out_features),在 LM 最后将 d_model -> vocab_size。参数尺寸为 (d_out, d_in)。
class Linear(nn.Module):
def __init__(
self,
in_features: int,
out_features: int,
device: torch.device | None = None,
dtype: torch.dtype | None = None,
):
super().__init__()
std = math.sqrt(2.0 / (in_features + out_features))
self.weight = nn.Parameter(
nn.init.trunc_normal_(
torch.empty(
(out_features, in_features),
device=device,
dtype=dtype,
),
std=std,
a=-3 * std,
b=3 * std,
)
)
def forward(self, x: Float[Tensor, " ... d_in"]) -> Float[Tensor, " ... d_out"]:
return x @ self.weight.T
2.2 Embedding Module
Embedding 主要做映射操作,即 vocab_size -> d_model,关联到 torch 的张量操作就是索引操作,参数尺寸为 (vocab_size, d_model):
class Embedding(nn.Module):
def __init__(
self,
vocab_size: int,
d_model: int,
device: torch.device | None = None,
dtype: torch.dtype | None = None,
):
super().__init__()
std = 1.0
self.weight = nn.Parameter(
nn.init.trunc_normal_(
torch.empty((vocab_size, d_model), device=device, dtype=dtype),
std=std,
a=-3 * std,
b=3 * std,
)
)
def forward(self, token_ids: Int[Tensor, " ..."]) -> Float[Tensor, " ... d_model"]:
return self.weight[token_ids]
2.3 Transformer Block
Transformer Block 架构如下,先经过 Self-Attention 层,再经过一个 FFN:
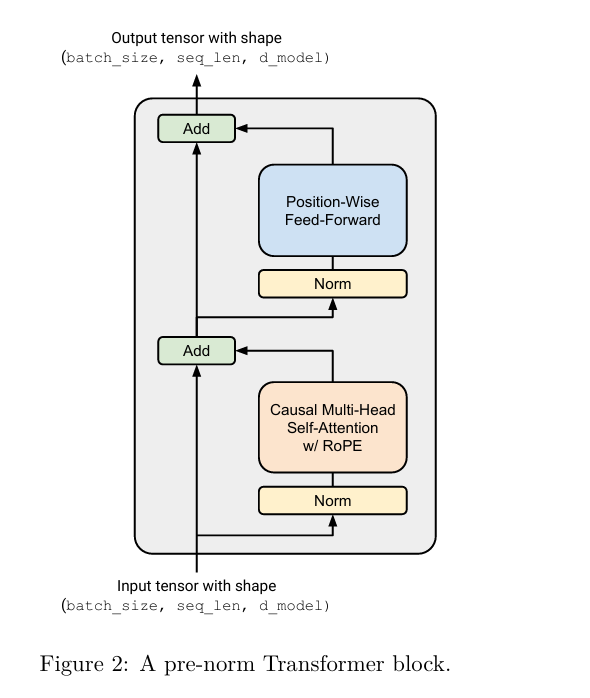
代码如下:
class TransformerBlock(nn.Module):
def __init__(
self,
d_model: int,
num_heads: int,
d_ff: int,
max_seq_len: int,
theta: float,
):
super().__init__()
self.ln1 = RMSNorm(d_model)
self.attn = MultiheadSelfAttention(d_model, num_heads, theta, max_seq_len)
self.ln2 = RMSNorm(d_model)
self.ffn = SwiGlu(d_model, d_ff)
def forward(
self, x: Float[Tensor, " ... seq_len d_model"]
) -> Float[Tensor, " ... seq_len d_model"]:
seq_len = x.size(-2)
token_positions = torch.arange(seq_len, device=x.device)
x = x + self.attn(self.ln1(x), token_positions)
x = x + self.ffn(self.ln2(x))
return x
2.3.1 Root Mean Square Layer Normalization
在 Transformer Block 中,每经过一个子模块首先需要 Layer Norm,这里采用 RMS Norm,具体公式如下
其中为可学习的参数,尺寸为(d_model,)。根据文档,代码实现时需要注意精度问题,因此代码如下:
class RMSNorm(nn.Module):
def __init__(
self,
d_model: int,
eps: float = 1e-5,
device: torch.device | None = None,
dtype: torch.dtype | None = None,
):
super().__init__()
self.eps = eps
self.weight: Float[Tensor, " d_model"] = nn.Parameter(
torch.ones(d_model, device=device, dtype=dtype)
)
def forward(
self, x: Float[Tensor, " ... d_model"]
) -> Float[Tensor, " ... d_model"]:
x_normed = self._norm(x.float()).type_as(x)
return self.weight * x_normed
def _norm(self, x: Float[Tensor, " ..."]) -> Float[Tensor, " ..."]:
return x * x.pow(2).mean(-1, keepdim=True).add(self.eps).rsqrt()
Note (为什么使用 LN 而不是 BN)
2.3.2 Position-Wise Feed-Forward Network
对于 FFN,常见的激活函数有
后来引入 GLU (Gated Linear Units) ,即将 GLU 的门控激活函数替换为 Swish,即为 SwiGLU其中尺寸为(..., d_model),,尺寸为 (d_ff, d_model),用于把从空间映射到空间,尺寸为 (d_model, d_ff) 用于变换回空间。一般 或者 。class SwiGlu(nn.Module):
def __init__(
self,
d_model: int,
d_ff: int,
device: torch.device | None = None,
dtype: torch.dtype | None = None,
):
super().__init__()
self.w1 = Linear(d_model, d_ff, device, dtype)
self.w2 = Linear(d_ff, d_model, device, dtype)
self.w3 = Linear(d_model, d_ff, device, dtype)
def forward(
self, x: Float[Tensor, " ... d_model"]
) -> Float[Tensor, " ... d_model"]:
return self.w2(silu(self.w1(x)) * self.w3(x))
2.3.3 Causal Multi-Head Self-Attention
多头注意力其实非常简单,本质就是维度变换而已,即
Q, K, V = (
rearrange(X, "... seq (h d_k) -> ... h seq d_k", h=self.num_heads)
for X in (Q, K, V)
)
最后再把多头拼回来
output = rearrange(output, "... h seq_len d_k -> ... seq_len (h d_k)")
完整实现如下:
class MultiheadSelfAttention(nn.Module):
def __init__(
self,
d_model: int,
num_heads: int,
theta: float | None = None,
max_seq_len: int | None = None,
):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.q_proj = Linear(d_model, d_model)
self.k_proj = Linear(d_model, d_model)
self.v_proj = Linear(d_model, d_model)
self.output_proj = Linear(d_model, d_model)
if theta is not None and max_seq_len is not None:
self.positional_embedding = RotaryPositionalEmbedding(
theta, self.d_k, max_seq_len
)
else:
self.positional_embedding = None
def forward(
self,
x: Float[Tensor, " ... seq_len d_model"],
token_positions: Int[Tensor, " ... seq_len"] | None = None,
) -> Float[Tensor, " ... seq_len d_model"]:
seq_len = x.size(-2)
mask = torch.tril(
torch.ones(
seq_len,
seq_len,
device=x.device,
dtype=torch.bool,
)
)
Q, K, V = self.q_proj(x), self.k_proj(x), self.v_proj(x)
Q, K, V = (
rearrange(X, "... seq (h d_k) -> ... h seq d_k", h=self.num_heads)
for X in (Q, K, V)
)
if self.positional_embedding:
Q = self.positional_embedding(Q, token_positions)
K = self.positional_embedding(K, token_positions)
output = scaled_dot_product_attention(Q, K, V, mask)
output = rearrange(output, "... h seq_len d_k -> ... seq_len (h d_k)")
return self.output_proj(output)
2.3.4 Scaled Dot-Product Attention
注意力模块是最重要的核心,这里实现纯函数,以计算注意力
其中,,。在计算 softmax 时需要进行掩码:
mask = torch.tril(torch.ones(seq_len, seq_len, dtype=torch.bool)
最后按照公式计算即可:
def scaled_dot_product_attention(
Q: Float[Tensor, " ... queries d_k"],
K: Float[Tensor, " ... keys d_k"],
V: Float[Tensor, " ... keys d_v"],
mask: Bool[Tensor, " ... queries keys"] | None = None,
) -> Float[Tensor, " ... queries d_v"]:
d_k = Q.size(-1)
scores = Q @ K.transpose(-2, -1) / math.sqrt(d_k)
if mask is not None:
scores = scores.where(mask, float("-inf"))
attention_weights = softmax(scores, dim=-1)
output = attention_weights @ V
return output
最后是 softmax 实现,只需要注意减去最大值的技巧即可:
def softmax(x: Float[Tensor, " ..."], dim: int = -1) -> Float[Tensor, " ..."]:
x_max = x.max(dim=dim, keepdim=True).values
x_exp = torch.exp(x - x_max)
return x_exp / x_exp.sum(dim=dim, keepdim=True)
2.3.5 Relative Positional Embeddings
RoPE 考虑将维向量分为组,每一组看作二维平面,对于每个二维平面,RoPE 应用一个旋转矩阵。即设有序列,考虑分块对角矩阵
每一个块矩阵为其中,,为超参数,一般取。对于向量,作变换此时注意到关键一步这表明内积仅与相对位置有关,因此完成相对位置编码。在实际实现中,我们通过以下方式计算
因此代码如下:class RotaryPositionalEmbedding(nn.Module):
def __init__(
self,
theta: float,
d_k: int,
max_seq_len: int,
):
super().__init__()
self.register_buffer(
"cis_cached",
self._init_cache(theta, d_k, max_seq_len),
persistent=False,
)
def forward(
self,
x: Float[Tensor, " ... seq_len d_k"],
token_positions: Int[Tensor, " ... seq_len"],
) -> Float[Tensor, " ... seq_len d_k"]:
cos, sin = self.cis_cached[:, token_positions]
return (x * cos) + (self._rotate_half(x) * sin)
@staticmethod
def _rotate_half(
x: Float[Tensor, " ... d_k"],
) -> Float[Tensor, " ... d_k"]:
"""Rotate (x1, x2, x3, x4, ...) to (-x2, x1, -x4, x3, ...)"""
x1, x2 = x[..., ::2], x[..., 1::2]
return torch.stack((-x2, x1), dim=-1).reshape_as(x)
@staticmethod
def _init_cache(
theta: float,
d_k: int,
max_seq_len: int,
) -> Float[Tensor, "2 max_seq_len d_k"]:
freqs = theta ** (-torch.arange(0, d_k, 2) / d_k)
pos = torch.arange(max_seq_len)
freqs = torch.outer(pos, freqs)
freqs = freqs.repeat_interleave(2, dim=-1)
return torch.stack((freqs.cos(), freqs.sin()))
3. Training a Transformer LM
3.1 Cross-entropy loss
交叉熵计算公式为
对于多分类问题,假设有个类别,则其中,且。注意到
因此我们额外引入log_softmax 函数:def log_softmax(x: Float[Tensor, " ..."], dim: int = -1) -> Float[Tensor, " ..."]:
x_max = x.max(dim=dim, keepdim=True).values
x_exp = torch.exp(x - x_max)
return x - x_max - x_exp.sum(dim=dim, keepdim=True).log()
注意到,element-wise 乘法等价于 index 操作,因此直接使用 torch.gather 简化:
def cross_entropy(
inputs: Float[Tensor, " ... seq_len vocab_size"],
targets: Int[Tensor, " ... seq_len"],
) -> Float[Tensor, ""]:
log_probs = log_softmax(inputs)
loss = -log_probs.gather(-1, targets.unsqueeze(-1))
return loss.mean()
3.2 AdamW
Adam 的梯度更新公式为
其中AdamW 在此基础上加上了
class AdamW(optim.Optimizer):
def __init__(
self,
params: Iterable[torch.nn.Parameter],
lr: float = 1e-3,
betas: tuple[float, float] = (0.9, 0.999),
eps: float = 1e-8,
weight_decay: float = 0.01,
):
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)
super().__init__(params, defaults)
def step(self, closure: Callable | None = None):
loss = None if closure is None else closure()
for group in self.param_groups:
lr = group["lr"]
beta1, beta2 = group["betas"]
eps = group["eps"]
weight_decay = group["weight_decay"]
for p in group["params"]:
if p.grad is None:
continue
state: dict[str, Any] = self.state[p]
# if state is empty dict, initialize
if not state:
state.update(t=0, m=torch.zeros_like(p), v=torch.zeros_like(p))
state["t"] += 1
self._update_param(
p,
state["m"],
state["v"],
state["t"],
lr,
beta1,
beta2,
eps,
weight_decay,
)
return loss
@staticmethod
def _update_param(
p: torch.nn.Parameter,
m: torch.Tensor,
v: torch.Tensor,
t: int,
lr: float,
beta1: float,
beta2: float,
eps: float,
weight_decay: float,
):
grad = p.grad.data
m.mul_(beta1).add_(grad, alpha=1 - beta1)
v.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
bias_correction1 = 1 - beta1**t
bias_correction2 = 1 - beta2**t
step_size = lr * (bias_correction2**0.5) / bias_correction1
p.data.addcdiv_(m, v.add_(eps).sqrt(), value=-step_size)
p.data.mul_(1 - lr * weight_decay)
3.3 Learning rate scheduling
Optimizer 是对步长的调节,Scheduler 是对学习率的调节。这里采用 Cosine annealing learning rate schedule 余弦退火学习率调度,思路大体为 warm up 阶段线性增长至 ,再余弦退火至 ,公式为
其中为 warm up 时间,为余弦退火时间。def get_lr_cosine_schedule(
it: int,
max_learning_rate: float,
min_learning_rate: float,
warmup_iters: int,
cosine_cycle_iters: int,
) -> float:
if it < warmup_iters:
return it / warmup_iters * max_learning_rate
if it > cosine_cycle_iters:
return min_learning_rate
decay_ratio = (it - warmup_iters) / (cosine_cycle_iters - warmup_iters)
cos_factor = 0.5 * (1 + math.cos(decay_ratio * math.pi))
return min_learning_rate + (max_learning_rate - min_learning_rate) * cos_factor
3.4 Gradient clipping
梯度 clipping 思路比较简单,设定阈值,当总梯度范数超过该阈值时压缩到该阈值。
def gradient_clipping(parameters: Iterable[torch.nn.Parameter], max_l2_norm: float):
grads = [p.grad for p in parameters if p.grad is not None]
if not grads:
return
total_norm = sum(grad.norm().pow(2) for grad in grads).sqrt()
if total_norm <= max_l2_norm:
return
scale_factor = max_l2_norm / (total_norm + 1e-6)
for grad in grads:
grad.mul_(scale_factor)
4. Train Loop
4.1 Data Loader
在写 Data Loader 之前,要额外说明一点是必须先把数据集使用先前的 Tokenizer encode 为 1 维向量(这里需要参考 pretokenize 中的方法切分成 chunk 并行处理),使用以下方式读取数据集。
np.memmap(data_path, dtype=dtype, mode="r")
值得一提的是,虽然我们只想得到最新的 token,但实际上 Transformers 得到的是一个序列,其中
其中。因此数据集的 只需把 整体右移。def get_batch(
dataset: npt.NDArray[np.uint16],
batch_size: int,
context_length: int,
device: str,
) -> tuple[Int[Tensor, " batch cxt_len"], Int[Tensor, " batch cxt_len"]]:
start_indices = np.random.randint(0, len(dataset) - context_length, size=batch_size)
indices = np.add.outer(start_indices, np.arange(context_length))
x = dataset[indices]
y = dataset[indices + 1]
return (
torch.from_numpy(x).to(device, dtype=torch.long),
torch.from_numpy(y).to(device, dtype=torch.long),
)
4.2 Checkpointing
checkpoint 也比较简单,保存 state_dict 即可:
def save_checkpoint(
out: str | os.PathLike | typing.BinaryIO | typing.IO[bytes],
model: torch.nn.Module,
optimizer: torch.optim.Optimizer,
scheduler: torch.optim.lr_scheduler.LRScheduler,
iteration: int,
wandb_run_id: str | None = None,
):
checkpoint = dict(
model_state=model.state_dict(),
optim_state=optimizer.state_dict(),
iteration=iteration,
scheduler_state=scheduler.state_dict(),
wandb_run_id=wandb_run_id,
)
torch.save(checkpoint, out)
5. Generating text
generate text 难点在于 2 个。一个是 top p 采样实现,个人实现是对概率进行排序,再计算累计概率,最后对第一个超过 top_p 概率以后的部分掩码,保证在 probs 上原地进行,即:
def _top_p_mask(probs: Float[Tensor, "... vocab"], top_p: float):
sorted_probs, sorted_indices = probs.sort(descending=True)
cumulative_probs = sorted_probs.cumsum(-1)
sorted_mask = cumulative_probs >= top_p
# Shift right to keep the first token that crosses threshold
sorted_mask[..., 1:] = sorted_mask[..., :-1].clone()
sorted_mask[..., 0] = False
# Map back to original order using scatter
mask = torch.zeros_like(probs, dtype=torch.bool)
mask.scatter_(dim=-1, index=sorted_indices, src=sorted_mask)
probs.masked_fill_(mask, 0.0)
第二个难点在于有 batch 个 prompts 时,如果设定了 eos_token_id,则可能停止的时机不太一致。这里我们使用 finished: Bool[Tensor, 'batch_size'] 记录是否完成,对于完成的 token 使用 eos_token_id 填充。完整代码为:
@torch.no_grad()
def generate(
self,
input_ids: Int[Tensor, " ... seq_len"],
max_tokens: int = 100,
temperature: float | None = None,
top_p: float | None = None,
eos_token_id: int | None = None,
) -> Int[Tensor, " ... total_len"]:
batch_size = input_ids.size(0) if input_ids.dim() > 1 else 1
finished = torch.zeros(batch_size, dtype=torch.bool, device=input_ids.device)
for _ in range(max_tokens):
logits = self.forward(input_ids)
next_token_logits = logits[..., -1, :]
if temperature is not None:
next_token_logits.div_(temperature)
probs = softmax(next_token_logits)
if top_p is not None:
self._top_p_mask(probs, top_p)
next_token = torch.multinomial(probs, num_samples=1)
if eos_token_id is not None:
finished |= next_token.squeeze(-1) == eos_token_id
next_token[finished] = eos_token_id
input_ids = torch.cat((input_ids, next_token), dim=-1)
if eos_token_id is not None and finished.all():
break
return input_ids
目前的实现巧妙点在于兼容了 (seq_len,) 和 (batch, seq_len) 两种输入。